这是荣获“全球大模型第一股”桂冠成功并在港交所敲钟后,智谱创始人唐杰的首次登台;是完成5亿美元C轮融资后,Kimi创始人杨植麟首次对外阐述观点;是因履新腾讯广受外界关注后,腾讯“CEO/总裁办公室”首席AI科学家姚顺雨首次亮相;也是Qwen技术负责人林俊旸一次密集的观点输出。
这就是1月10日,由清华大学基础模型北京市重点实验室、智谱AI发起的AGI—Next前沿峰会。新京报贝壳财经记者在现场发现了一个细节:虽然上述四人所在的智谱、Kimi、元宝、千问几乎代表了当前中国基础大模型的“半壁江山”,但会议现场最中央的嘉宾位置给了包括中国人工智能领域“开山鼻祖”、91岁清华大学教授张钹等在内的四位重量级院士,除了唐杰作为主持人需要频繁上台外,杨植麟等坐在了第二排。
会议上,唐杰阐述了如何“让机器像人一样思考”,杨植麟展示了Kimi K2在训练过程中如何通过优化模型画出“2025年最漂亮的曲线图”。而在圆桌讨论环节,姚顺雨则详细阐述了自己履新腾讯后的感受,对中美AI行业不同的体感,以及对下一代AI范式的思考。
贝壳财经记者注意到,在这场时长约三个半小时、充满学术氛围的会议上,四位院士专家听到了最后。张钹院士甚至抽空儿做了一个PPT,并进行了总结发言。张钹说,“在大语言模型出现之前,我非常不赞成我的学生去创业。但大模型出现后,我觉得最优秀的学生应该去搞企业,因为人工智能会定义一切,也定义了未来的企业家。要把人工智能作为像水和电那样交给人类,企业家也必须担当起社会的责任。”

张钹院士在演讲中表示要“重新定义AI时代的企业家”。贝壳财经记者罗亦丹/摄
唐杰:像做咖啡一样专注做研究,AGI值得长期投入

智谱AI创始人、首席科学家唐杰现场发表演讲。主办方供图
作为本次活动的“东道主”,智谱创始人、首席科学家唐杰兼任了会场主持人的角色。贝壳财经记者注意到,在活动开始之前,不少行业人士,甚至包括记者自己都前去向他“恭喜上市”,但唐杰仍然保持着学者本色,礼貌回应后就一心沉浸在修改报告中。
唐杰的演讲题目是“让机器像人一样思考”,自2006年清华毕业至今,他刚好度过了20年。回首过往,唐杰总结自己“也就做了两件事”:一、当年的AMiner系统,二、现在的大模型。
从唐杰的身上,看不出一点公司创始人的商人色彩。他表示自己一贯有一个观点,就是“用像做咖啡一样的专注精神来做事”,而现在他碰到了AGI(通用人工智能),这正好是需要长期投入、长期做的一件事,“AGI不是短平快,今天我做明天就能开花结果,它很长期,很值得投入。”
因此,他带领团队果断暂停当时已具国际影响力的图神经网络、知识图谱研究,全员转向大模型领域。在他看来,2025年RLVR(可验证奖励强化学习)迎来爆发,让模型能够在可验证环境中自主探索,实现自我成长。但行业挑战依然存在,如何将可验证场景拓展到半自动甚至不可验证领域,成为全球科研团队共同面对的课题。
唐杰表示,2025年初,DeepSeek的横空出世让他及其团队意识到,Chat范式已接近发展瓶颈,行业新方向应是“让 AI 真正做事”。基于这一判断,智谱选择整合 Coding(编程)、Agentic(智能体)、Reasoning(推理)三大核心能力,于7月发布GLM-4.5模型。该模型在12项基准测试中表现亮眼。
但对于当前的中美模型差距,唐杰强调行业需保持清醒认识:中美大模型领域的差距仍在拉大,美国在闭源模型领域的深耕值得国内团队警惕。展望未来,AGI的发展需突破三大核心能力:一是多模态感统,实现多源信息的统一感知;二是完善记忆系统,构建从个人三级记忆到人类第四级记录的完整体系;三是探索反思与自我认知能力,这一具有争议性的研究方向,仍具备极高的探索价值。
对于2026年的发展规划,唐杰透露,智谱将聚焦三大方向:持续推进Scaling(记者注:可理解为数据规模)已知边界与未知范式的探索;推进模型架构创新,解决超长上下文与知识压缩的核心问题;深耕多模态感统技术,助力 AI 真正进入物理世界。他坚信,AI for Science 即将迎来爆发期,而 AGI 的终极探索,正是让机器像人类一样探索未知——这既需要科研团队的专注坚守,更需要敢于挑战 “不可能”的勇气。
杨植麟:当你有一个优雅的方法,就可以得到一个优雅的结果
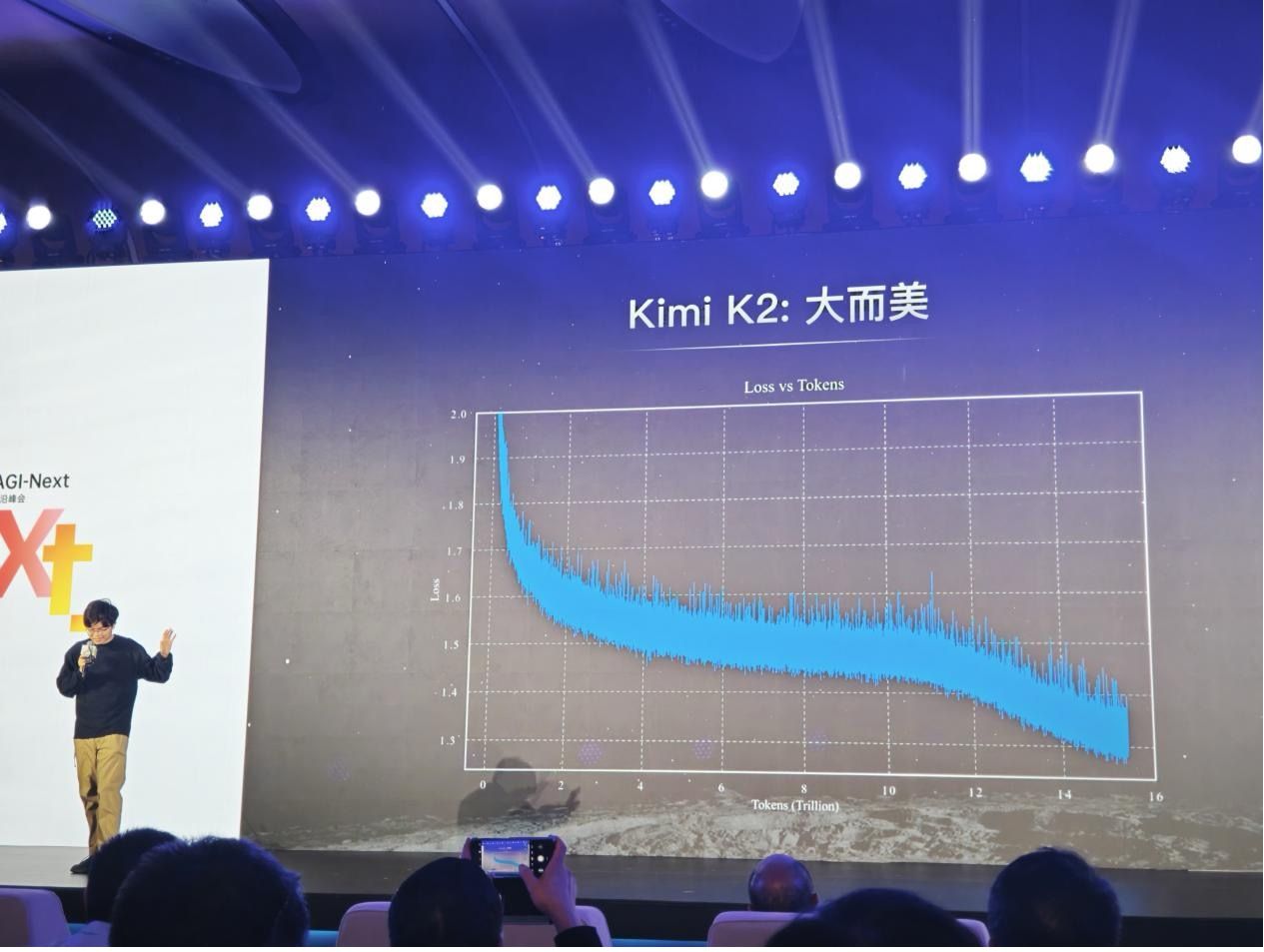
月之暗面创始人杨植麟现场发布演讲。贝壳财经记者罗亦丹/摄
“当你有一个优雅的方法,就可以得到一个优雅的结果。”在AGI-Next前沿峰会上,月之暗面Kimi创始人、CEO杨植麟展示了Kimi K2在训练过程中如何通过QK-Clip驯服Muon,降低Logits的过程。他将一张平稳下降的Loss(模型训练损失值)曲线图称为“2025年见过最漂亮的东西”。
十几天前,12月31日,杨植麟曾发布内部信,其中提到,(作为)中国首个万亿参数基座模型、第一个开源的Agentic Model、在最核心Benchmark(模型性能基准测试),例如在HLE上超越OpenAI,第一次成功使用二阶优化器做大规模训练,K2系列模型让Kimi从中国走向了世界。
基于Kimi K2、K2 Thking等模型在技术上取得的突破,杨植麟对中国的开源模型充满信心。峰会上,杨植麟直言:我觉得很多中国的开源模型逐渐成为新的标准。
K2之后,Kimi下一步将从哪些方面破解人工智能领域尚未解决的问题?
杨植麟表示,K2之后,Kimi在持续探索下一代模型有可能长什么样。技术路线上,Kimi将在目前开源的Kimi Linear的基础上做更多的优化和改进来训练K3模型,最重要的一个改进方向是优化大模型的线性注意力机制在长距离任务上的表现。
对于业界普遍关注的Scaling问题,杨植麟介绍,Kimi将在K2的基础上做更多的Scaling,但同时他也提出不一样的观点,Scaling并不只是加算力,而是做更多技术改进,这些技术改进也会等效变成Scaling的优势,“我觉得模型是一个很不一样的东西,做模型的过程本质上是创造一种价值观。”
内部信中,杨植麟透露,公司近期完成5亿美元C轮融资且大幅超募,当前现金持有量超过100亿元。杨植麟也在内部信中表现出十足的底气,他写道,相较于二级市场,我们判断还可以从一级市场募集更多资金,“所以我们短期不着急上市。当然未来我们计划将上市作为手段来加速推动AGI,择时而动,主动权掌握在我们手中。”
演讲尾声,杨植麟分享了一段和Kimi探讨“AGI/ASI的到来,可能带来更美好的未来,但也可能威胁人类,作为研究AGI/ASI的科学家,是否还要继续开发”的对话,也借此表达他本人对这一问题的看法。Kimi给出的答案是,即使存在风险,仍然会继续开发,因为放弃AGI/ASI,意味着放弃了人类文明的潜力。
“我希望在接下来的十年、二十年时间,继续把K4、K5到K100做得更好。”杨植麟坦言,所有技术的突破都伴随着风险,不能因为恐惧而停滞不前,反而应该进一步去突破,同时,控制好风险。
姚顺雨:腾讯To C基因更强,自己更多思考如何让大模型给用户提供更多价值

腾讯“CEO/总裁办公室”首席AI科学家姚顺雨参与圆桌讨论。主办方供图
相比唐杰和杨植麟,姚顺雨的出场是在峰会的圆桌讨论环节,且出场极富“戏剧性”——远程连线的他在圆桌刚开始被投屏到了会场大屏幕之上,引发了现场笑声,他也调侃了起来“我现在是不是有一个巨大的脸在会场?”
作为前OpenAI研究员,姚顺雨拥有在中美明星公司从事AI研究的经历。对于自己在腾讯的“新身份”,姚顺雨表示腾讯是To C基因更强的公司,“我们会思考怎么样能够让今天的大模型或AI的发展给用户提供更多价值,核心思考是我们发现很多时候需要的不是更大的模型、更强的强化学习或模仿学习,而是额外的Context(上下文信息)”。
针对中美实验室的研究文化,姚顺雨提出了自己的建议。他认为“在中国大家还是更喜欢做更安全的事情”。如预训练这种已经被证明可行的方向,即使技术难度很高,中国团队也能在短时间内攻克;但对于长期记忆、持续学习这类未知的领域,大家却很少愿意涉足。他呼吁中国研究机构跳出“打榜”的束缚,“Claude的模型可能在编程或者软件工程的榜单上也不是最高的,但大家都知道这个东西最好用”。他认为,DeepSeek的做法值得借鉴,这家公司不刻意追求榜单排名,而是更关注“什么是正确的事情”“什么是用户能体验出好或者不好的事情”。
在峰会现场,姚顺雨还分享了对AI市场分化的观察。他认为当前AI行业正呈现两大分化趋势:一是To C和To B赛道的明显分野,二是垂直整合与模型应用分层的路径分化。
谈及To C和To B的差异,姚顺雨用ChatGPT和Claude Code作为典型案例。“我们今天用ChatGPT和去年相比的话,感受差别不是太大”,他直言,对于To C用户而言,大部分人大部分时候不需要用到顶尖的智能,“很多用户甚至把大模型当作搜索引擎的加强版,很多时候也不知道该怎么去用,把它的智能给激发出来”。
但To B赛道的逻辑截然不同。姚顺雨强调,智能越高,代表生产力越高,商业价值也越大。他观察到一个有趣的现象:美国的企业客户愿意为最强的模型支付溢价。比如一个顶尖模型每月定价200美元,而次一级的模型定价50美元或20美元,但企业更倾向于选择前者。在他看来,To B市场上,强模型和弱模型的分化会越来越明显。
未来三到五年,国产AI可能领先吗?
圆桌最后,关于“未来3—5年全球最领先的AI公司是中国团队的概率有多大”的问题,姚顺雨、林俊旸、唐杰也均给出了自己的观点。
姚顺雨的回答很乐观:概率很高。他的信心源于中国在多个领域的成功经验:“中国能够复现很多成功案例,一些局部还会做得更好,这在制造业已经不断地发生。”不过他也坦言,当前全球的生产力和To B模型应用,大多诞生于美国,核心原因是美国企业的支付意愿更强,商业环境更成熟。“今天在国内做To B很难,所以很多公司会选择出海或者国际化的路径”。在他看来,构建起完善的本土To B市场,同时具备国际竞争能力,是中国AI崛起的必要前提。
而更重要的,是主观层面的突破。姚顺雨肯定了中国AI人才的实力:“中国有非常多非常强的人才,任何一个事情只要被证明能做出来,很多人都会非常积极地尝试,并且想做得更好。”但他也表示,国内想要突破新范式或者做冒险探索的人还不够多,这背后涉及经济环境、商业环境和文化等多重因素。
“我们到底能不能引领新的范式,这可能是今天唯一要解决的问题”,姚顺雨强调,在商业、产业设计和工程层面,中国已经具备比肩甚至超越美国的能力,唯独在前沿范式的探索上,还需要更多有创业精神和冒险精神的人,敢于投身未知的领域。
林俊旸则指出了中美算力的差距,“美国算力可能整体比我们大1—2个数量级,我看到OpenAI等投入了大量的算力到下一代研究中,而我们则捉襟见肘,可能交付就占到了绝大部分算力,这是一个比较大的差异。”
但他也表示,随着教育的普及和研究人员年龄逐渐年轻,当前中国AI从业者的冒险精神正变得越来越强,“我属于90年代靠前,(姚)顺雨90年代靠后,我们团队里还有许多00后,未来我们的创新概率也会越来越大。”
唐杰则坦言,中国企业界的AI Lab(AI实验室)与美国仍存在差距,但他对未来充满信心。他认为,中国的机会在于三个方面:一是90后、00后一代创业者敢于冒险,愿投身核心创新;二是营商环境正逐步改善,若能进一步优化,让创新者摆脱繁杂事务、聚焦研发,将释放更大潜力;三是从业者的坚持——身处环境持续变好的时代,经历本身即财富,只要敢闯敢试、久久为功,未必不能走到最后。
新京报贝壳财经记者 罗亦丹 张晓慧
编辑 岳彩周
校对 刘军





