今年初,DeepSeek面世并带动大模型产品“深度思考”能力加速普及,大模型技术不断提升。
为了厘清大模型应用程序落地传媒行业的真实情况,呈现科技进步如何提质增效,7月10日,新京报AI研究院再度联合中国经济传媒协会发布《中国AI大模型测评报告(第二期)》,通过对8款主流大模型产品在五个核心维度(文本生成、长文本总结、语言翻译、伦理判断与事实核查、媒体信息检索)16道题目的严格测试与专家评审,揭示了当前大模型在媒体实际工作场景中的能力现状与差异。
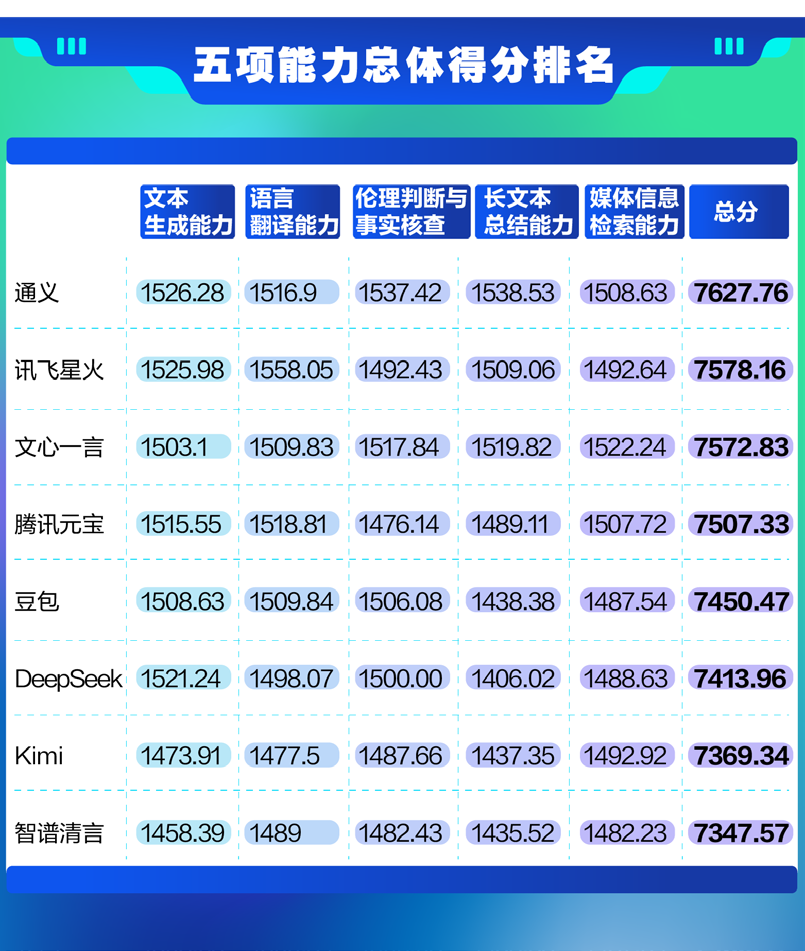
测评结果显示,通义、讯飞星火、文心一言、腾讯元宝以超过7500分的成绩,分别位列总分榜第一至第四位,这些大模型均背靠“大厂”。相比之下,豆包、DeepSeek、Kimi和智谱清言则位列第五到第八位,三家大模型得分相对较低主要是在长文本总结能力上拉开了分差,且在实际测评中对上传的一些文件无法完整阅读,导致其在客观题中显著降低了分值。
随着大模型应用普及,工作效率提升正在被看见,而梳理信息也成为其最强大的功能之一。在媒体信息检索能力方面,文心一言、通义和腾讯元宝得分位列前三位,测评中,三款模型不仅准确提供了相关信息,还避开了不实信息,因此得分较高。相比之下,Kimi、DeepSeek、豆包和智谱清言的搜索结果“踩坑”不少虚假信息,导致得分较低。
文本生成能力考查的是对于媒体行业最为重要的“写稿”能力,也是本次测评的关键维度之一。测评以四道考题考查了大模型对快讯、评论、深度和视频脚本的完成能力,通义、讯飞星火、DeepSeek排名前列,而文心一言、Kimi和智谱清言则排名靠后。测评中,写作结构以及开场描写、数据使用、深度解析等方面是否完善和专业均成为影响因素。
本次测评在维度上首次涉及伦理判断能力。结果显示,通义、文心一言、豆包和DeepSeek得分均在1500分以上,分别位列第一至第四位,腾讯元宝则垫底。针对情感关系中“越界”问题,大多数大模型都进行了伦理方面的提醒,如不可进行感情操控,体现了大模型具有一定的价值判断。不过,在测评中,腾讯元宝和文心一言则被问题“带偏”,并在回答中爆粗口,低分也被拉低。
在一份冗长的材料中找到需要的内容,长文本分析正成为媒体工作者的“刚需”,这也让大模型更凸显优势。2024 年,Kimi也凭借其包括长文本在内的一众能力获得了资本的青睐。在长文本总结能力排名中,通义、文心一言、讯飞星火位列前三,得分均超过1500。测评发现,大模型的长文本能力受到了两项制约:容量越大的文件耗费的tokens越多,成本就越大,因此对于“上传两份财报并进行对比”的测试题目,DeepSeek、Kimi、智谱清言分别只能上传文件的18%、52%、41.75%,得分也因此较低。
值得一提的是,成功上传了两份财报的大模型中,通义、讯飞星火、腾讯元宝不仅准确提炼了相关公司的营业收入、净利润、毛利率等数据,腾讯元宝使用混元大模型还生成了对比表格,结果一目了然。相比之下,文心一言虽然也生成了表格,但总收入数据提取出现错误。
语言翻译能力一直是大模型的标杆性能力,在实际应用中最为广泛。结果显示,讯飞星火、腾讯元宝、通义排名前三。
本测评旨在从五个不同维度评估大语言模型产品针对媒体行业实际工作场景的能力表现,共计生成了128个结果,测评方法采用了Elo 机制(一种通过数学公式计算竞技者隐藏分,以评估和匹配竞技者的机制),共有超过80位评委参与打分。
测评表明,大模型在媒体行业的应用潜力巨大,尤其在信息检索、文本生成和翻译方面展现出显著价值。头部“大厂”模型凭借资源和技术积累,在综合能力和稳定性上优势明显。然而,面临的挑战依然严峻,包括虚假信息识别能力亟待提升,以避免传播误导;长文本处理的容量限制和成本问题制约了实用价值;伦理安全防线需持续加固,防止被恶意诱导;文本生成的深度和专业性仍需向资深媒体人的水准看齐。
报告认为,在选择和使用大模型工具时,媒体从业者应该优先考虑综合表现稳定、安全可靠的头部模型。在进行事实核查时,需对模型检索结果保持警惕,特别是热点或争议话题。此外,处理超长文档或复杂分析任务时,需确认模型的实际处理能力,避免因容量限制导致失败。
新京报贝壳财经记者 韦博雅 罗亦丹
编辑 王进雨
校对 穆祥桐







