在智能体活跃,token(词元)消耗量呈指数级增加的2026年,token经济以及算力的受重视程度与日俱增。以“龙虾”OpenClaw为代表的智能体需要消耗算力,用户必须从token供应商处获取API key(密钥),才能让这些智能体正常运行。
不过,许多人不知道的是,即便是同一款模型,根据供应商的不同,其token的“质量”也会存在差异。近日,清华大学计算机系长聘教授、博士生导师,清程极智首席科学家翟季冬接受了新京报贝壳财经记者的采访,揭开了token经济中这一“隐秘的角落”。
此外,作为曾带领清华团队十五次获得国际大学生超算竞赛冠军的指导老师,翟季冬和团队成员也对当前国产算力芯片如何与大模型进行适配,以及二者之间“推理引擎”层的作用,对新京报贝壳财经记者进行了科普。

清华大学计算机系长聘教授、博士生导师,清程极智首席科学家翟季冬回答记者提问。罗亦丹/摄
同一模型,便宜token有可能更“费钱”
“token是今年最火的词,但token底层涉及很多技术。”翟季冬开门见山地说,在他看来,token产业可以分为三层:底层是在芯片上部署大模型,生产token的生产层;中间层是作为token供应商转运分发token的流通层;最上层则是个人和企业用户直接调用API消费token的使用层。
这三层结构听上去跟电力系统有些相似,但翟季冬强调,两者的成熟度完全不在一个量级,“当我们用电时,不用担心发出来的电有‘差别’,但token不同,同样的模型、同样的价格,token质量却可能参差不齐。”
他告诉记者,实际上,token供应商的指标有很多,除了通俗易懂的价格、上下文长度外,还有首字延迟、吞吐量,以及普通用户较难理解的精度、 KV Cache(键值缓存)命中等。
而这些“隐秘的细节”可能决定模型的效果和token消耗的大小。
在模型效果方面,翟季冬举例称,比如模型发布时可能采用了BF16精度,但有些供应商会把它量化成INT8甚至INT4来部署,好处是算力消耗减半,可以承载更多用户,代价是模型能力被“裁剪”了,不再是原汁原味的效果。
据了解,FP16、INT8等专业术语指的是大模型推理的精度,数字(4/8/16/32/64)代表位数,一般来说,位数越高,计算精度越高、结果越准,但速度越慢、消耗算力越大;位数越低,速度越快、越省算力,但会轻微损失模型效果。
而在token消耗量方面,翟季冬给记者算了一笔账:同样的模型,一家供应商报价每百万token3元,另一家报价1元,看似便宜的那家,实际总成本可能反而更高。“它有两行报价,一行是token命中,可能是一毛钱,token不命中是一块钱。但是它的token生产做得很差,你的这些请求都不命中,最后反而费钱。”
清程极智联合创始人师天麾解释称,这里的核心技术是KV Cache(键值缓存)管理——在多轮对话场景中,缓存命中可以节省90%的成本,但不同供应商的缓存管理水平差距巨大,其中报价低的服务商也许缓存并不高,本该节省的那些缓存没能节省,导致总成本很高。但服务商在卖token时,一般不会直接说明缓存命中率是多少,甚至有些服务商直接不给缓存命中的优惠价格。
针对这一乱象,清程极智推出了AI Ping一站式大模型服务评测与API智能路由平台,目前,平台已接入30余家主流服务商、600余个大模型服务,覆盖文本、图片、视频等全场景;通过7×24小时多地域分布式监测,实时输出延迟、吞吐、可靠性、价格等核心指标。
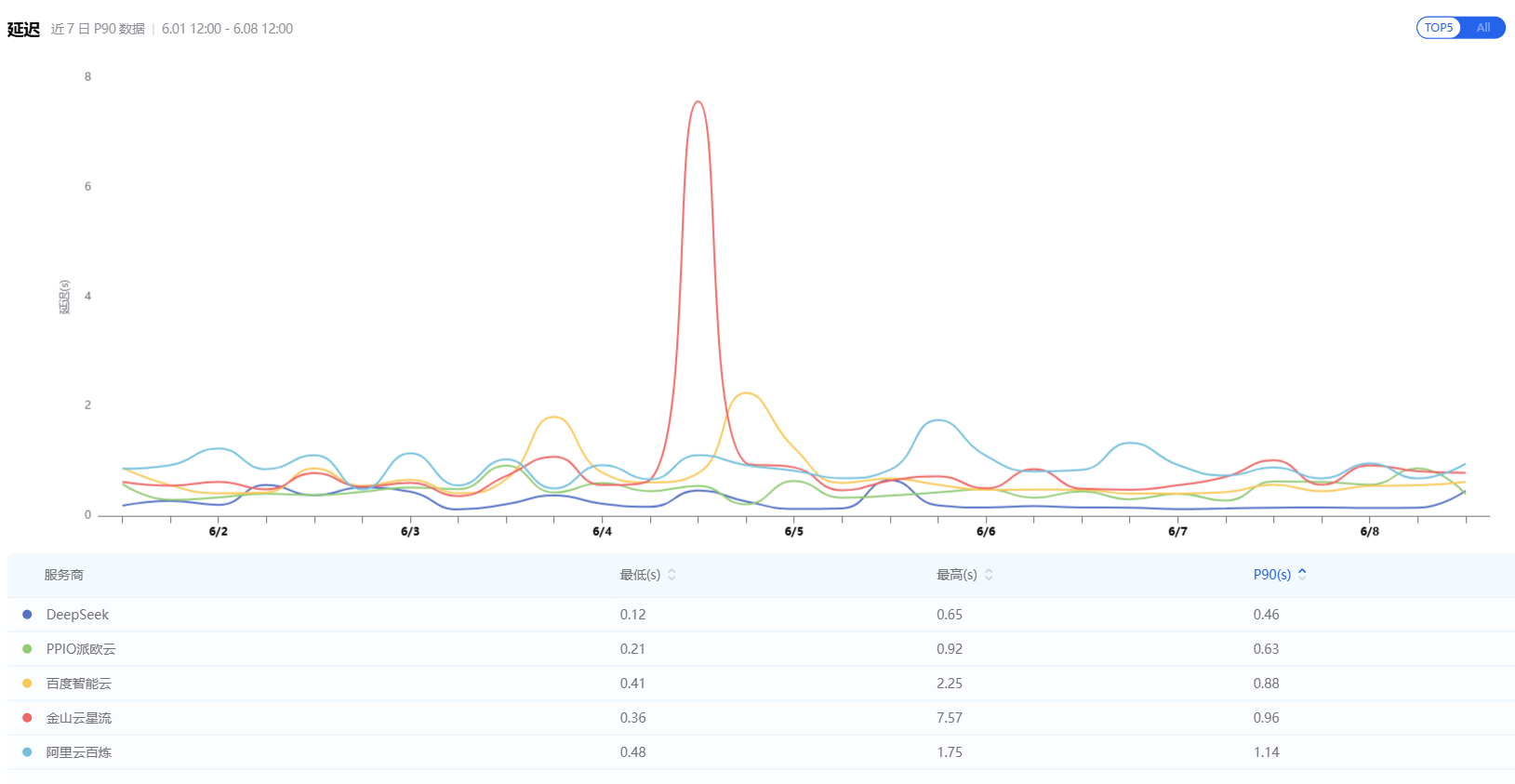
不同供应商提供的DeepSeek-V4-Pro模型的token延迟情况对比图。数据来源:aiping.cn
6月8日,新京报贝壳财经记者登录AI Ping平台,随机查看了DeepSeek-V4-Pro模型不同token供应商的延迟情况,发现其记录了价格、延迟、吞吐等指标。如对于延迟这一指标,一些服务商的曲线波动极大,而最为稳定的则是DeepSeek官方提供的token。
“中国的电力系统在全世界是第一的,我们希望通过各种努力,能够把我国token服务的质量和性能也做到全世界第一。”翟季冬说。
芯片发展趋势:支持的精度类型越来越多
token质量的差异,追根溯源要落到芯片和推理引擎上。一个容易被忽略的事实是:在国产算力和国产模型之间,并不是直接对接的关系,中间还隔着一层至关重要的“推理引擎”。这层软件承上启下,决定了芯片的算力能不能被高效释放,也决定了最终生产出来的token质量够不够好。
翟季冬用精度问题向贝壳财经记者解释了推理引擎的价值——“很多人认为芯片正在向精度越来越高发展,但事实上,芯片正在向支持的精度类型越来越多发展,例如,传统CPU可能只支持三、四种精度类型,而现在的AI芯片能支持十几种,从FP64、FP32、FP16到FP8、FP4,还有INT8、INT4等整数精度,每一种都有不同的性能和效果权衡。”
“模型不是说一定要选最高的精度才好,因为精度更高的同时,也更慢,每个模型会选一个恰到好处的精度。”清程极智联合创始人唐适之补充道,“目前来讲,主流模型的选择往往跟随英伟达走——比如FP8就是英伟达推出Hopper系列显卡时新增的精度,DeepSeek觉得FP8最适合自己的模型,就选了这个标准。”
但问题随之而来:国产芯片的精度支持并不完全跟英伟达对齐。“对DeepSeek来讲,国产卡有的精度过高有的精度过低,使用起来无论如何都是有损失的。”
这正是推理引擎的用武之地。翟季冬告诉记者,海外主流推理引擎如vLLM、SGlang对英伟达、AMD的生态支持更好,但对国产芯片的优化投入有限。针对大模型部署成本高、国产算力适配不足的痛点,清程极智推出了自主研发的国产推理引擎赤兔,其对国产模型、国产芯片的支持在很多情况下比vLLM、SGlang要更好。
这种优势不只是体现在精度适配层面。唐适之介绍,不同国产芯片的硬件特性差异很大,比如有些卡的张量计算能力和标量计算能力之间的权衡跟英伟达不一样,有些卡的卡间互联方式也不同,推理引擎需要针对这些特点做定制化设计。“我们要真正地根据国产卡上面的特点来选我们的实现方案,而不是说看英伟达上面有这个精度就选这个精度。”
“我们将持续深耕AI基础设施领域,坚持核心技术自主可控,不断迭代赤兔推理引擎对国产芯片的适配能力,完善AI Ping评测与路由服务,联动国产算力、国产模型、行业应用等产业链伙伴,打造高效、普惠、安全的国产AI基础设施体系,响应国家‘人工智能+’行动,以技术创新推动中国AI产业高质量发展。”翟季冬说。
新京报贝壳财经首席记者 罗亦丹 编辑 陈莉 校对 柳宝庆






